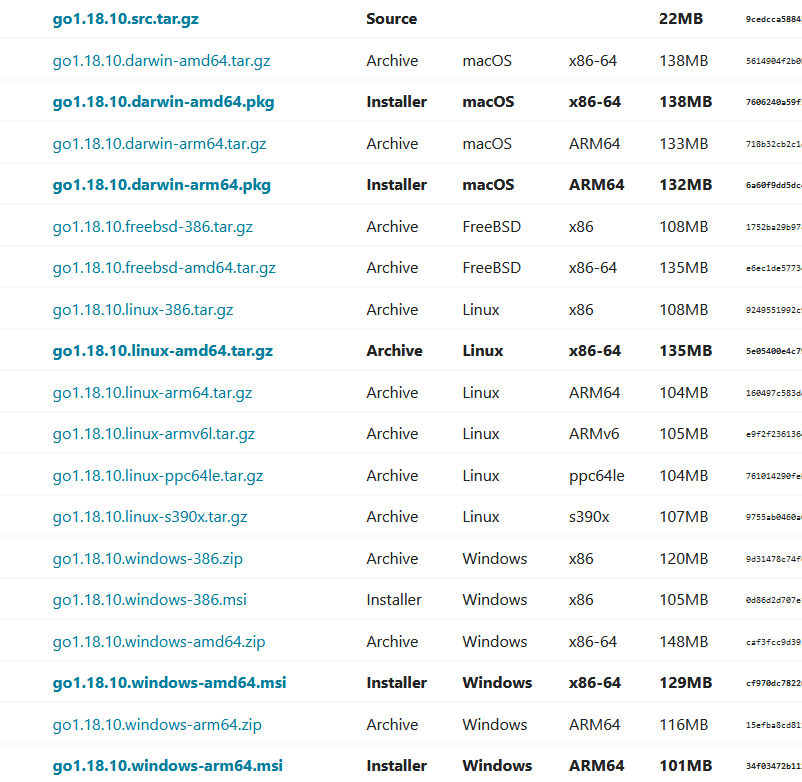
tkinter.TclError: wrong # args: should be "wm iconphoto window ?-default? image1 ?image2 ...?"
是由于在 Windows 上调用 root.iconphoto(False, photo) 时,传入了 None(即 self._create_icon() 返回 None),而 iconphoto 不接受 None 作为图像参数 —— 这在部分 Windows 版本(尤其是未安装 PIL 的环境)中会直接崩溃。
✅ 根本原因:
您的系统中未安装 Pillow(PIL),导致 _create_icon() 中的 from PIL import Image 失败,回退逻辑也因异常未正确返回默认图标,最终向 iconphoto 传入了 None。
安装 Pillow(推荐 · 完整功能)
Cmd
pip install Pillow