一、背景
在Linux中,线程是一种轻量级的执行单元,可以在进程内独立运行。线程可以分为普通线程和实时线程,它们之间的区别在于其调度和优先级设置。
SCHED_OTHER,普通的调度(非实时线程),应用层设置优先级0,调度器总会给此类线程分配一定的CPU资源,只不过是被分配到的频次和时间片长度较少。每1s中实时线程和普通线程的时间比例是95 :5。
普通线程没有固定的响应时间要求,它们的优先级由系统动态调整。Linux使用CFS调度器来管理普通线程。CFS调度器采用一种称为红黑树的数据结构来维护线程的优先级。每个线程都有一个vruntime值,它表示线程在运行队列中消耗的虚拟时间。CFS调度器会根据线程的vruntime值来确定运行的顺序。优先级较高的线程vruntime值较小,因此能够更早地获得CPU的时间片。
适用场景:实时性要求不高,但要求必须能被执行的线程。
SCHED_FIFO,抢占式调度(实时线程),实时先行,应用层设置优先级1-99,同一优先级的多个线程中,一旦某个抢占式线程获取CPU,除非被更高优先级线程抢占(比如在非实时线程中创建一个更高优先级的实时线程),或该线程主动让出CPU资源,否则该线程将会一直占用CPU(但总会分配一点资源给SCHED_OTHER非实时线程)。
适用场景:实时性要求高,不希望被频繁打断的任务。
SCHED_RR,轮询式调度(实时线程),实时循环,设置优先级1-99,以循环方式运行,每个线程都有一个时间片来执行任务,时间片耗尽后,该线程将被放入队列的末尾,而较低优先级的线程有机会执行。
适用场景:实时性要求高,允许被频繁打断的任务。
在Linux中,可以使用sched_setscheduler函数。这个函数允许我们选择普通线程或实时线程。对于普通线程,可以使用nice函数来动态调整优先级。对于实时线程,可以使用sched_setscheduler函数来设置其类型和优先级。
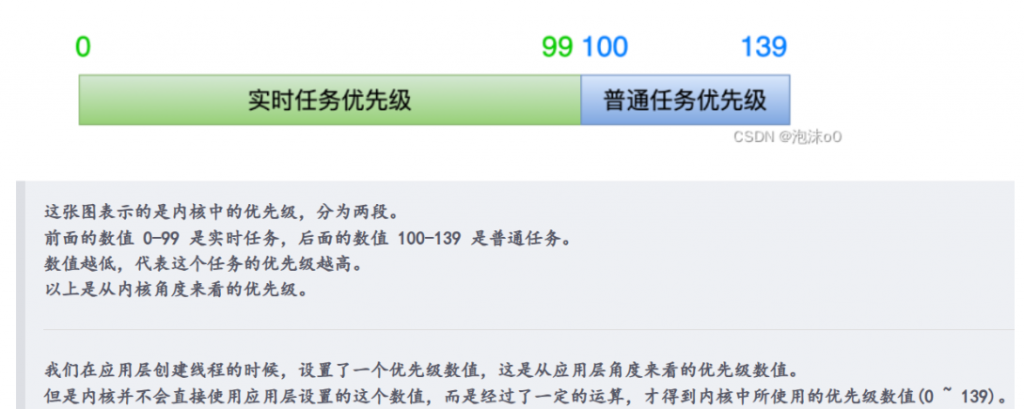
关于优先级高低和数值大小的关系,在应用层和内核中二者是相反的。
设置线程的优先级需要谨慎,因为过高的优先级可能会导致系统资源的过度占用,从而影响其他线程和进程的正常运行。另外,需要注意的是,只有具有足够权限的用户才能设置较高的实时线程优先级。
总结起来,Linux中的线程分为普通线程和实时线程。普通线程的优先级由系统动态调整,而实时线程的优先级由用户显式设置。通过合理地设置线程的优先级,可以提高系统的性能和响应时间。然而,设置线程的优先级需要慎重考虑,以避免影响其他线程和进程的正常运行。
二、方法
pthread_t pis_task;
pthread_attr_t attr;
struct sched_param sched_param;
// 初始化线程属性
pthread_attr_init(&attr);
// 设置线程为实时线程
pthread_attr_setinheritsched(&attr, PTHREAD_EXPLICIT_SCHED);
pthread_attr_setschedpolicy(&attr, SCHED_FIFO);
// 设置线程优先级
sched_param.sched_priority = THREAD_PRIORITY;
pthread_attr_setschedparam(&attr, &sched_param);
pthread_create(&pis_task, &attr, PrtMgr_Decode_Task, (void *)&PrintMgr_Init_colorId);
pthread_setname_np(pis_task, "name");